数字识别篇
本章将会对数字识别的部分进行讲解和部分实战
如果你对深度学习有着浓厚的兴趣,本章也可以带你简单的入门深度学习,训练自己的模型并实现部署
当然,老话题,我们在学习之前需要了解什么是机器学习、深度学习
两者的区别在哪里,该如何使用两者
什么是机器学习?
机器学习是人工智能的一个重要分支,它使计算机能够通过学习数据和模式来自动改进和优化算法。机器学习的核心在于让计算机从数据中学习规律和模式,并利用这些知识和模式进行预测、决策,以及自主学习特定知识和技能。机器学习算法包括但不限于聚类、分类、决策树、贝叶斯、神经网络和深度学习等,这些算法通过建立数学模型来解决最优化问题。
什么是深度学习?
深度学习是一种机器学习方法,它属于机器学习的分支。深度学习模仿人脑的工作原理,通过构建和训练多层神经网络来处理和解释复杂的数据,其核心组成部分是神经网络,由许多人工神经元组成,这些神经元通过学习算法来调整它们之间的连接权重。
它们的区别是什么?
1.数据依赖
深度学习与传统机器学习之间最重要的区别会随着数据规模的增大而表现出来。当数据很小时,深度学习算法表现不佳。这是因为深度学习算法需要大量数据才能完美理解它。另一方面,传统的机器学习算法及其手工制作的规则在这种情况下占据优势
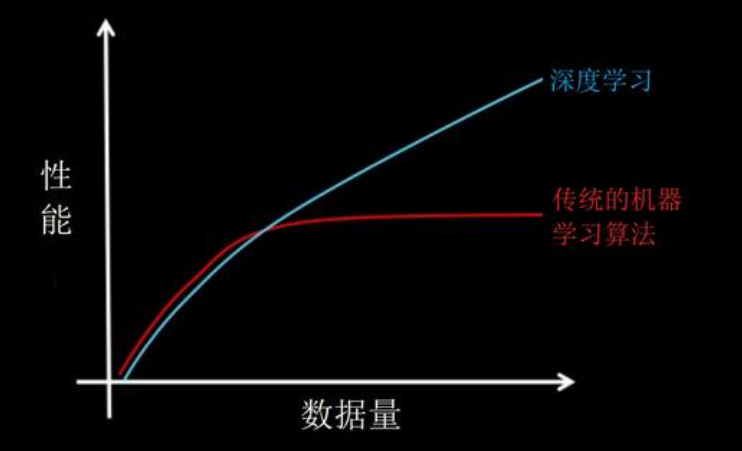
2.硬件依赖性
传统的机器学习可以在低端机器上运行,而深度学习算法则在很大程度上依赖于高端机器。这是因为深度学习算法的要求包括GPU,因为GPU是其工作中不可或缺的组成部分。深度学习算法本质上是做大量的矩阵乘法运算,而使用GPU可以有效的优化这些操作,而这就是使用GPU的目的。
3.特征工程
特征工程是将领域知识放入特征提取器的创建过程,用来降低数据的复杂性并使特征对于学习算法更加可见。就时间和专业知识而言,这个过程是困难而又昂贵的。
在机器学习中,大多数应用的特征需要由专家识别,然后根据领域和数据类型进行手动编码,要求非常的高
例如,特征可以是像素值,形状,纹理,位置和方向。大多数机器学习算法的性能取决于特征识别和特征提取的准确程度。
深度学习算法尝试从数据中学习高级特征。这是深度学习一个非常独特的部分,也是超越传统机器学习的重要部分。因此,深度学习减少了为每个问题开发新的特征提取器的任务。就像,卷积神经网络将尝试先学习底层特征,例如早期图层中的边缘和线条,然后是人脸的部分面部,最后是高级的面部识别

4.执行时间
通常,深度学习算法需要很长时间来训练。这是因为深度学习算法中有很多的参数,所以训练它们需要更长的时间。最先进的深度学习算法ResNet需要大约两周时间才能完全从0开始的训练。相比之下,机器学习的训练时间要短得多,从几秒钟到几小时不等
测试时间则完全颠倒。在测试时,深度学习算法运行的时间要少得多。而有些机器学习算法的测试时间则会随着数据的增加而增加,比如K近邻算法。当然,并不是所有的机器学习算法都是这样
5.可解释性
我们将可解释性作为比较机器学习和深度学习的一个因素。这个因素是深度学习在用于行业之前仍被反复思考的主要原因。
举个例子。假设我们使用深度学习自动为论文打评分。它在打分方面的表现的非常出色,接近人类的表现。但有一个问题就是它没有透露出为什么它给出了这个分数。虽然,你可以通过数学方法找出深层神经网络的哪些节点被激活,但我们不知道这些神经元是怎么建模的,以及这些神经元做了什么。所以我们无法解释结果。
另一方面,像决策树这样的机器学习算法为我们提供了清晰的规则,解释了为什么要选择这个内容,因此特别容易理解其背后的原理。因此,像决策树和线性/逻辑回归等算法广泛用于行业中,就是因为其结果的可解释性
因为其无法解释的特性,我们常常会说深度学习是在 "练丹"
相信你看到这里,已经对机器学习和深度学习有了一个初步的了解