卷积神经网络组成
卷积神经网络基本构成图:
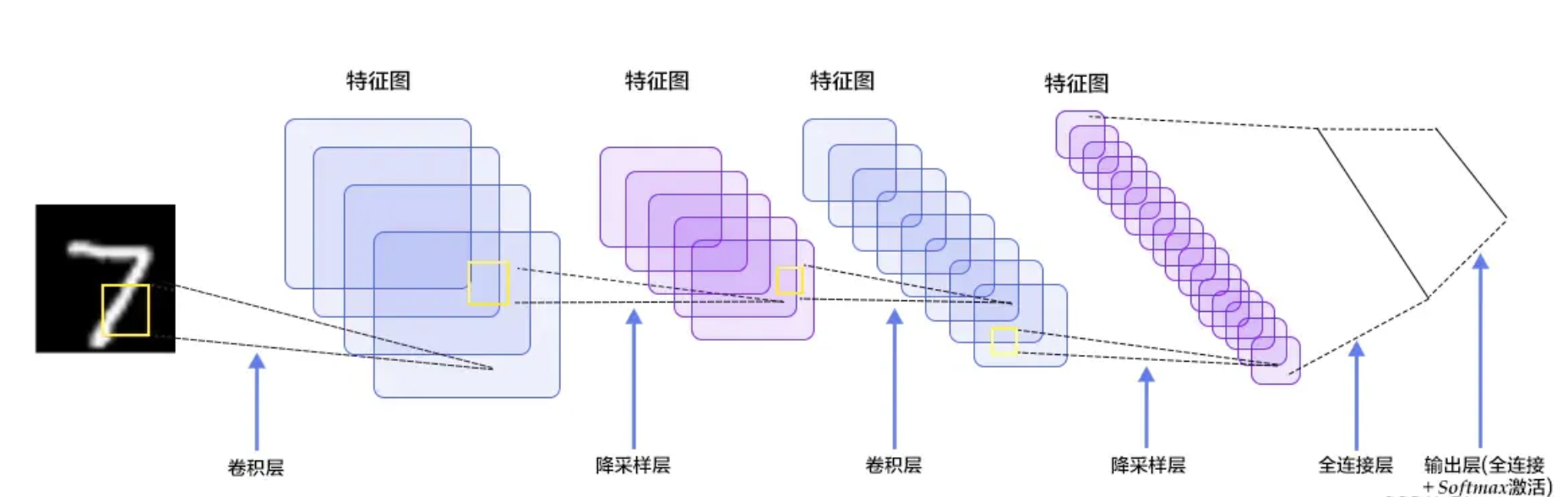
可以看到整个过程需要在如下几层进行运算:
- 输入层:输入图像等信息
- 卷积层:用来提取图像的底层特征
- 池化层:防止过拟合,将数据维度减小
- 全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
输出层:根据全连接层的信息得到概率最大的结果
可以看到其中最重要的一层就是卷积层,这也是卷积神经网络名称的由来,接下来一一进行介绍
输入层
这一层的主要工作就是输入图像等信息,因为卷积神经网络主要处理的是图像相关的内容,如下图所示的手写数字“8”的图像,计算机读取后是以像素值大小组成的二维矩阵存储的图像
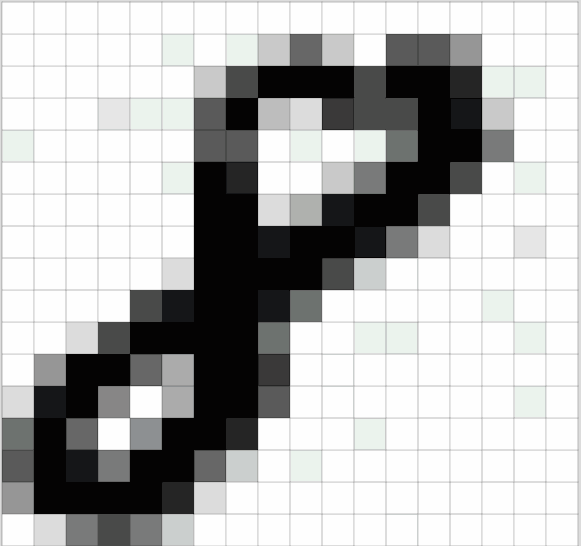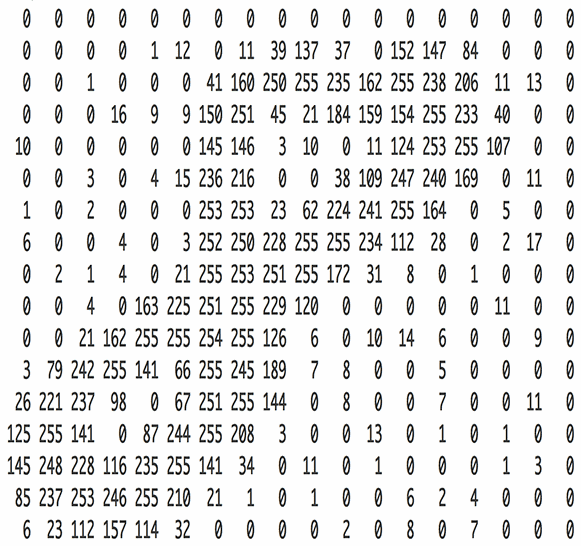
输入层的作用就是将图像转换为其对应的由像素值构成的二维矩阵,并将此二维矩阵存储,等待后面几层的操作
卷积层
那图片输入进来之后该怎么处理呢?假设我们已经得到图片的二维矩阵了,想要提取其中特征,那么卷积操作就会为存在特征的区域确定一个高值,否则确定一个低值。这个过程需要通过计算其与卷积核(Convolution Kernel)的乘积值来确定
假设我们现在的输入图片是一个人的脑袋,而人的眼睛是我们需要提取的特征,那么我们就将人的眼睛作为卷积核,通过在人的脑袋的图片上移动来确定哪里是眼睛,这个过程如下所示:
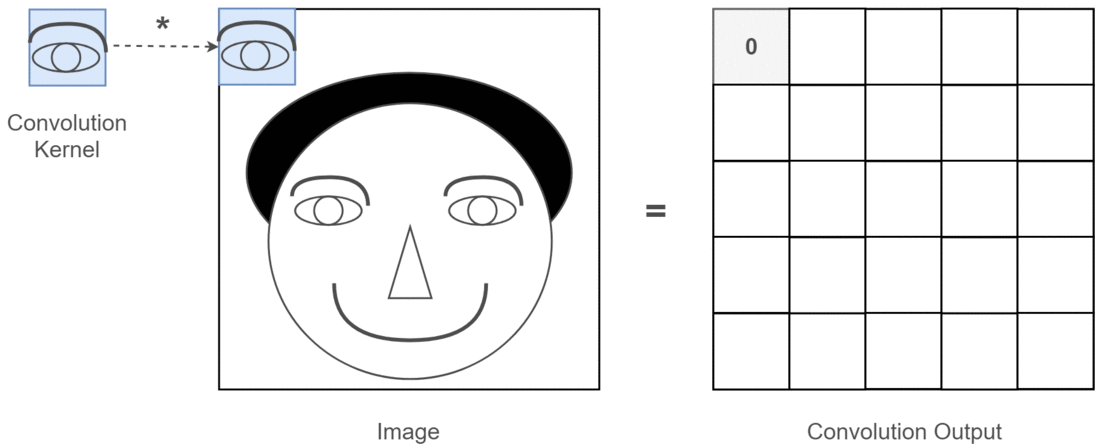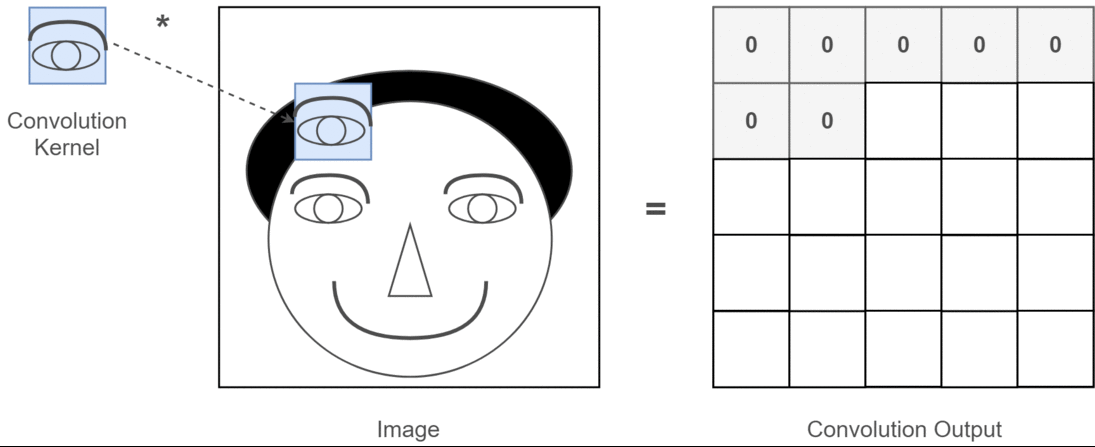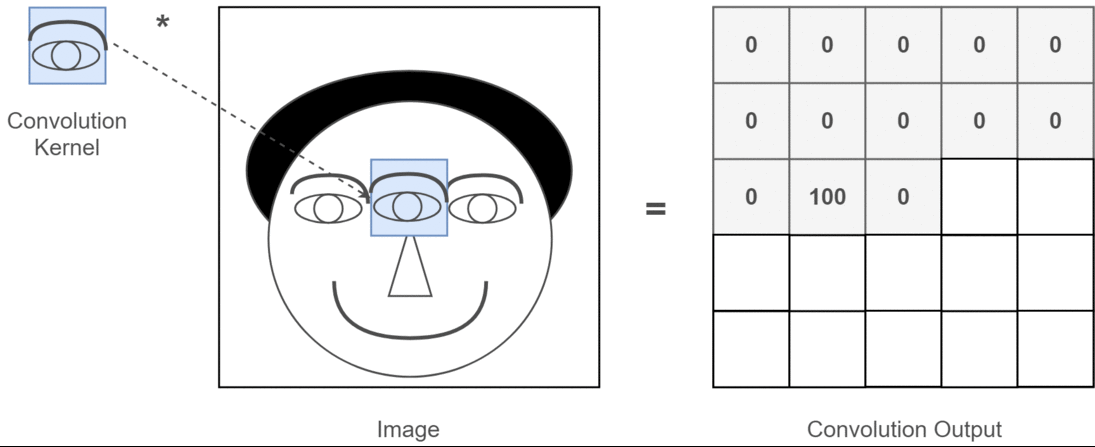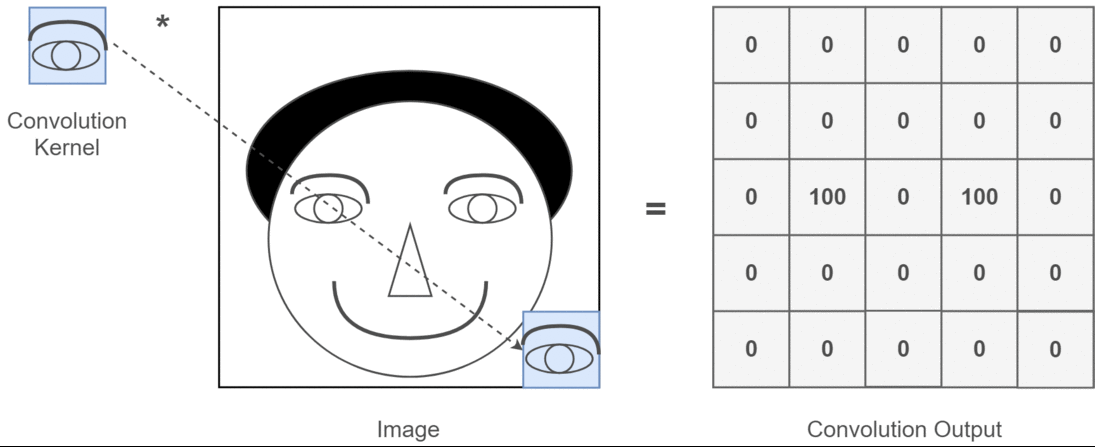
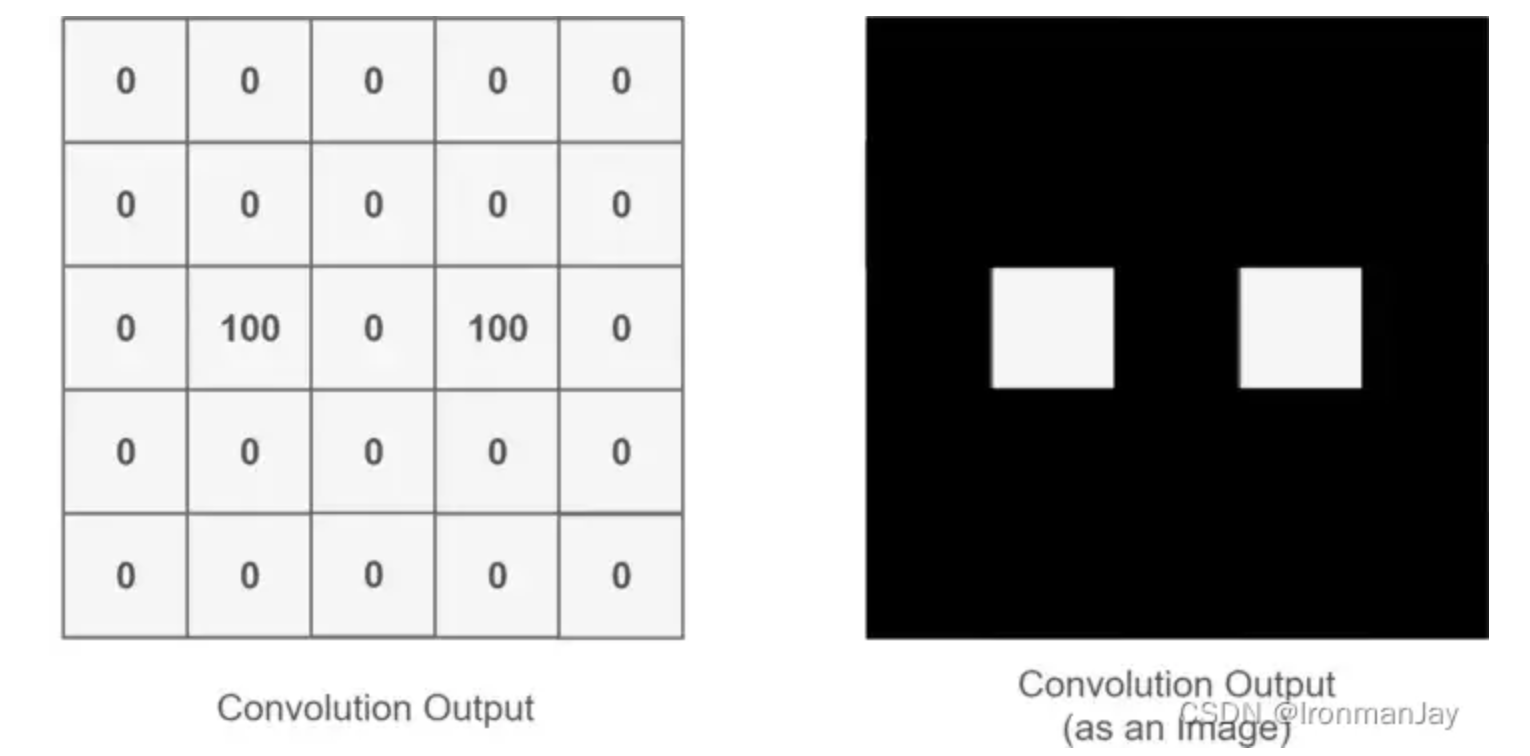
通过整个卷积过程又得到一个新的二维矩阵,此二维矩阵也被称为特征图(Feature Map),最后我们可以将得到的特征图进行上色处理(我只是打个比方,比如高值为白色,低值为黑色),最后可以提取到关于人的眼睛的特征,如下所示:
首先卷积核也是一个二维矩阵,当然这个二维矩阵要比输入图像的二维矩阵要小或相等,卷积核通过在输入图像的二维矩阵上不停的移动,每一次移动都进行一次乘积的求和,作为此位置的值,这个过程如下图所示:
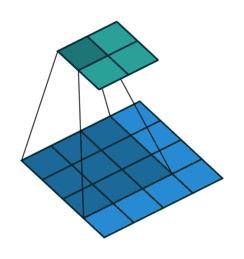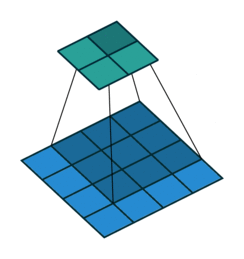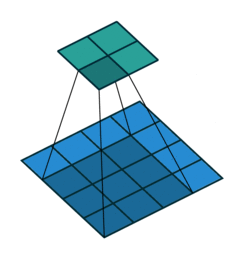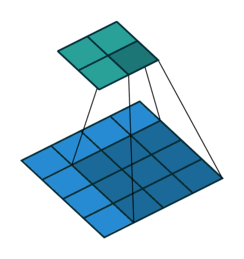
可以看到,整个过程就是一个降维的过程,通过卷积核的不停移动计算,可以提取图像中最有用的特征。我们通常将卷积核计算得到的新的二维矩阵称为特征图,比如上方动图中,下方移动的深蓝色正方形就是卷积核,上方不动的青色正方形就是特征图。
如果每次计算的时候,边缘只被计算一次,而中间被多次计算,那么得到的特征图也会丢失边缘特征,最终会导致特征提取不准确,那为了解决这个问题,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈,这样每个位置都可以被公平的计算到了,也就不会丢失任何特征,此过程可见下面两种情况,这种通过拓展解决特征丢失的方法又被称为Padding
- Padding取值为1,拓展一圈
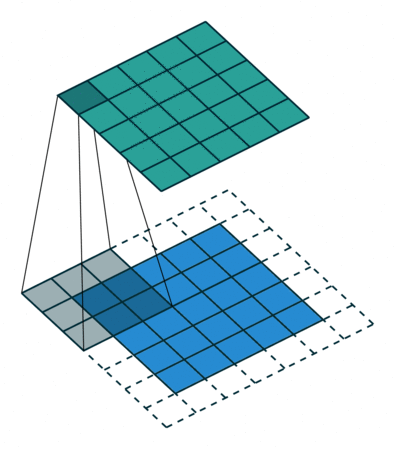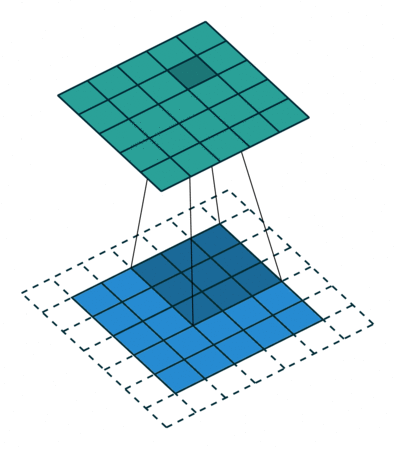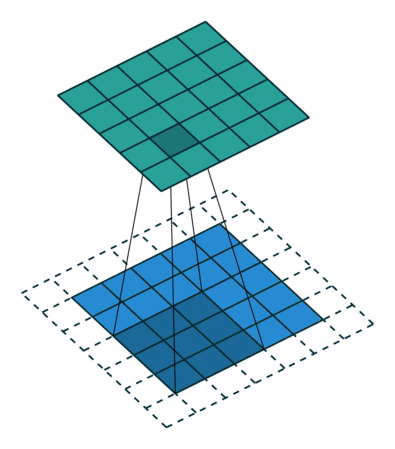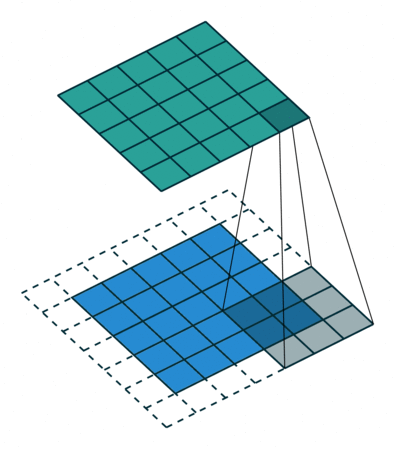
那如果情况再复杂一些呢?如果我们使用两个卷积核去提取一张彩色图片呢?之前我们介绍过,彩色图片都是三个通道,也就是说一个彩色图片会有三个二维矩阵,当然,我们仅以第一个通道示例,否则太多了也不好介绍。此时我们使用两组卷积核,每组卷积核都用来提取自己通道的二维矩阵的特征
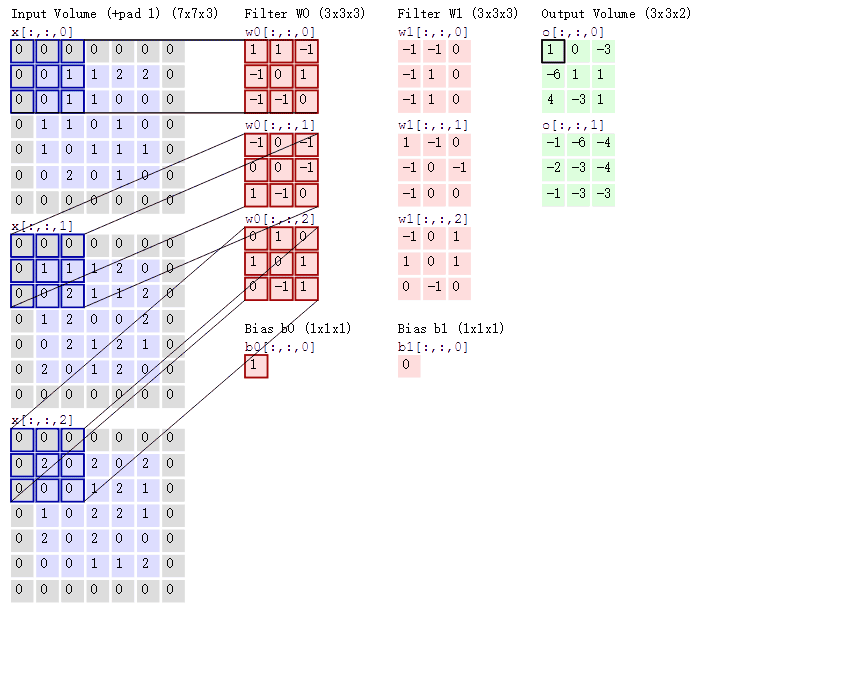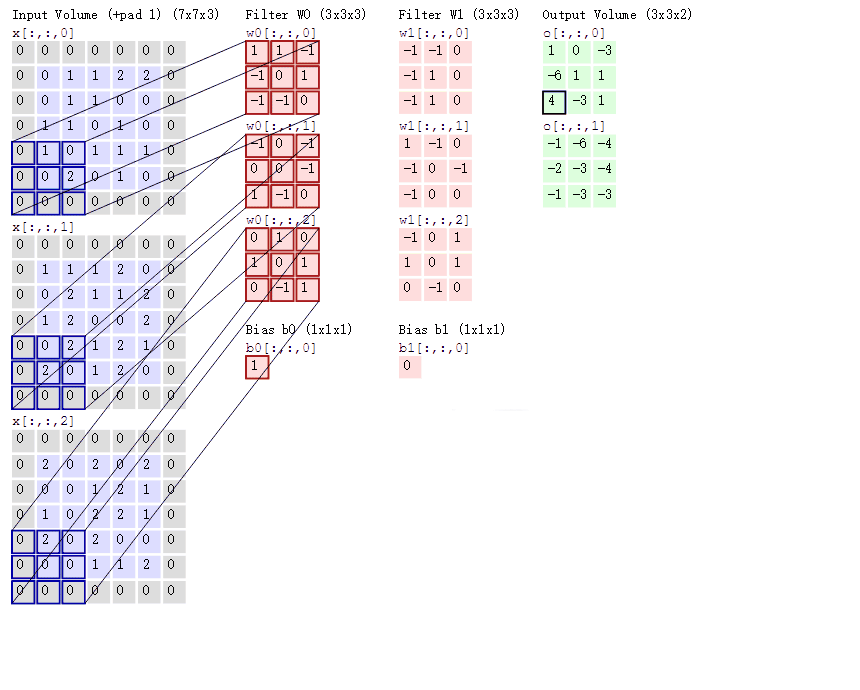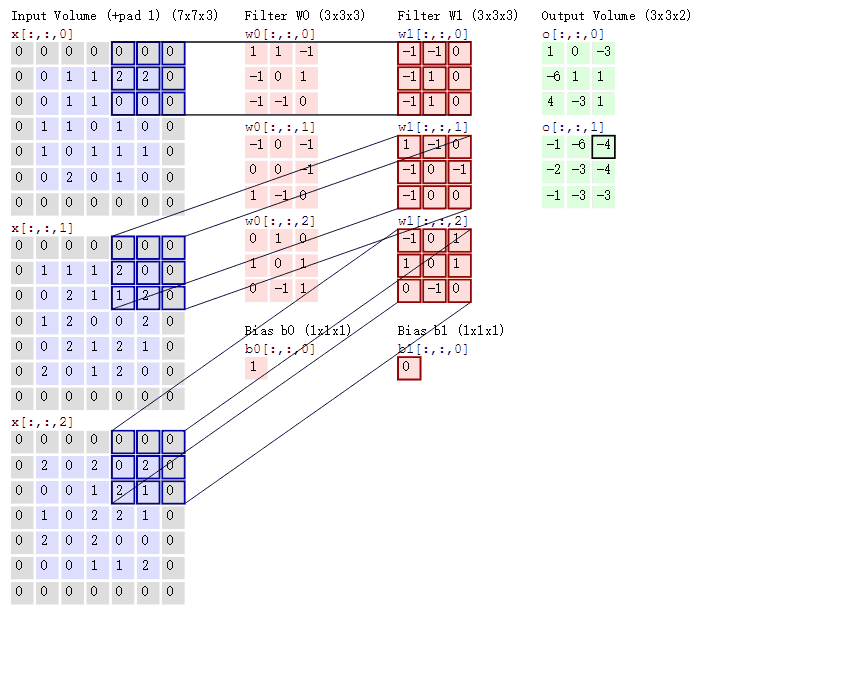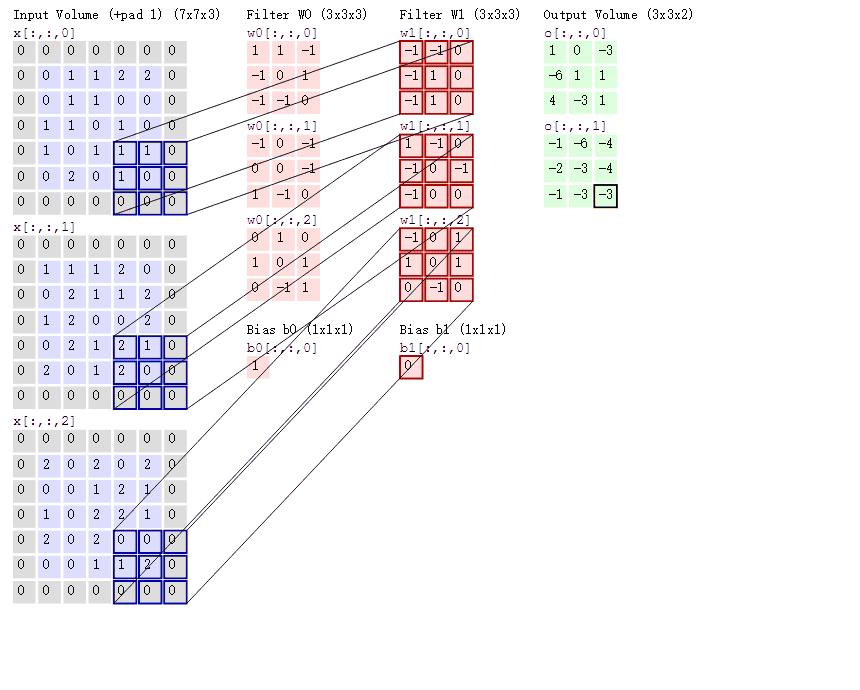
输入图片是彩色图片,有三个通道,所以输入图片的尺寸就是7×7×3,而我们只考虑第一个通道,也就是从第一个7×7的二维矩阵中提取特征,那么我们只需要使用每组卷积核的第一个卷积核即可,这里有一个Bias,其实它就是偏置项,最后计算的结果加上它就可以了,最终通过计算就可以得到特征图了。可以发现,有几个卷积核就有几个特征图,因为我们现在只使用了两个卷积核,所以会得到两个特征图。所以三个通道都进行卷积将会得到6个特征图
池化层
刚才我们也提到了,有几个卷积核就有多少个特征图,现实中情况肯定更为复杂,也就会有更多的卷积核,那么就会有更多的特征图,当特征图非常多的时候,意味着我们得到的特征也非常多,但是这么多特征都是我们所需要的么?显然不是,其实有很多特征我们是不需要的,而这些多余的特征通常会给我们带来如下两个问题:
过拟合
维度过高
为了解决这个问题,我们可以利用池化层,那什么是池化层呢?池化层又称为下采样,也就是说,当我们进行卷积操作后,再将得到的特征图进行特征提取,将其中最具有代表性的特征提取出来,可以起到减小过拟合和降低维度的作用,这个过程如下所示:
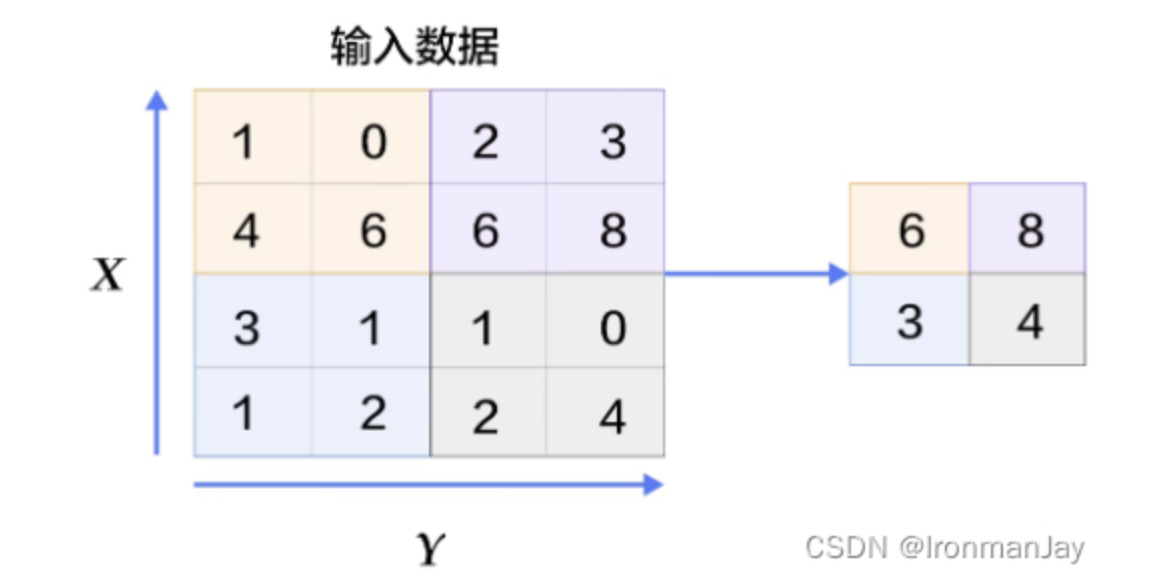
那么问题又来了,如何提取到最有代表性的特征呢,通常有两种方法
最大池化
顾名思义,最大池化就是每次取正方形中所有值的最大值,这个最大值也就相当于当前位置最具有代表性的特征,这个过程如下所示:
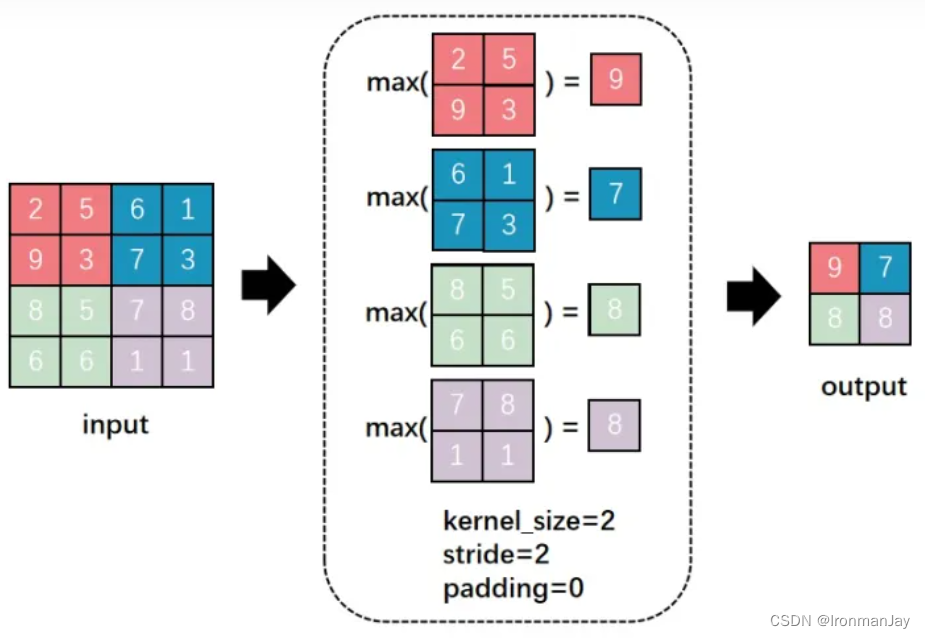
- kernel_size = 2:池化过程使用的正方形尺寸是2×2,如果是在卷积的过程中就说明卷积核的大小是2×2
- stride = 2:每次正方形移动两个位置(从左到右,从上到下),这个过程其实和卷积的操作过程一样
- padding = 0:这个之前介绍过,如果此值为0,说明没有进行拓展
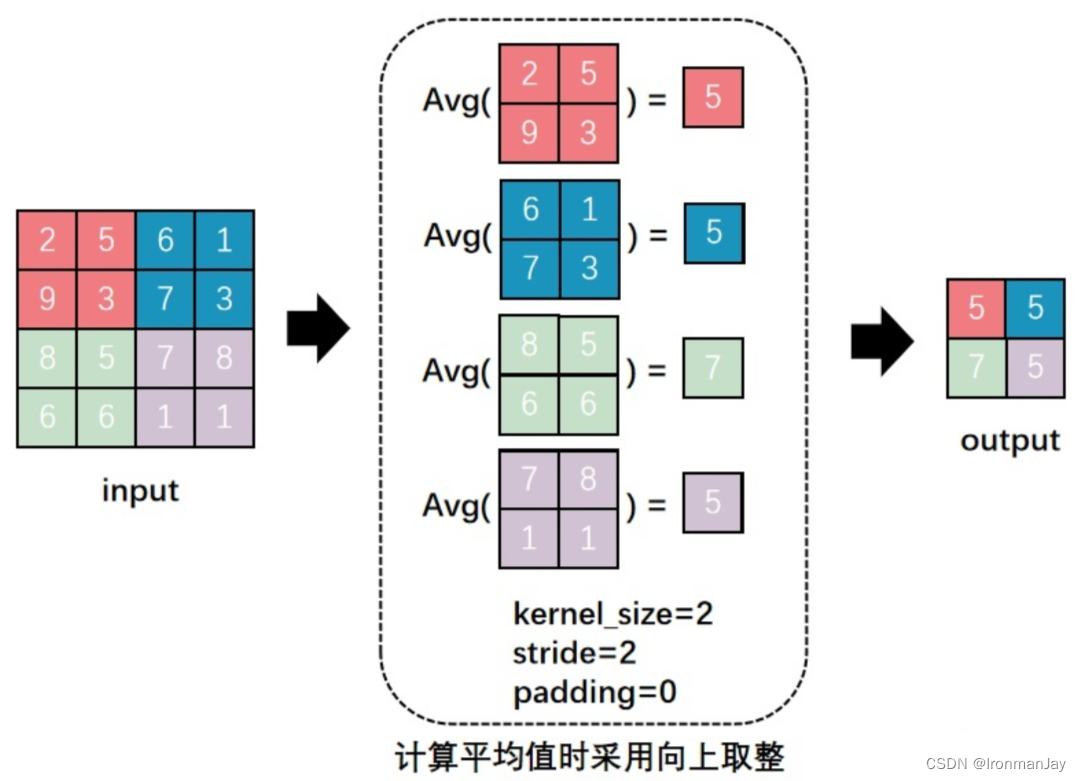
平均池化
平均池化就是取此正方形区域中所有值的平均值,考虑到每个位置的值对于此处特征的影响,平均池化计算也比较简单,整个过程如下图所示:
经过池化后,我们可以提取到更有代表性的特征,同时还减少了不必要的计算,这对于我们现实中的神经网络计算大有脾益,因为现实情况中神经网络非常大,而经过池化层后,就可以明显的提高模型的效率。所以说,池化层的好处很多,将其优点总结如下:
在减少参数量的同时,还保留了原图像的原始特征
有效防止过拟合
为卷积神经网络带来平移不变性
以上两个优点我们之前已经介绍过了,那什么又是平移不变性呢?可以用我们之前的一个例子,如下图所示:
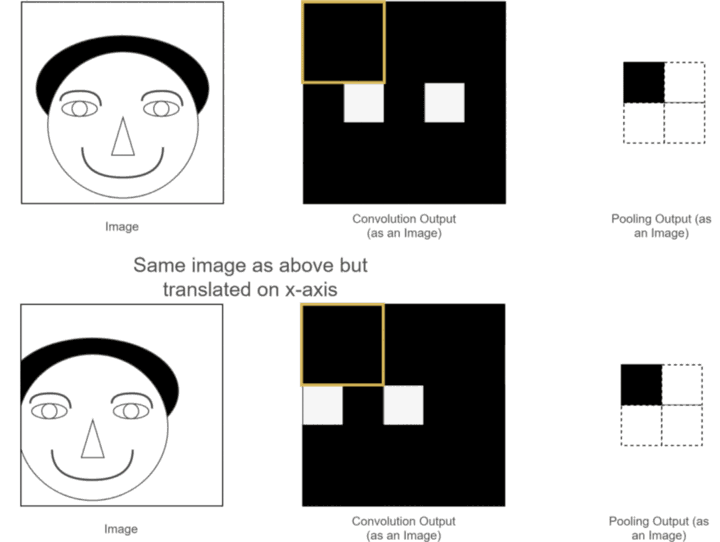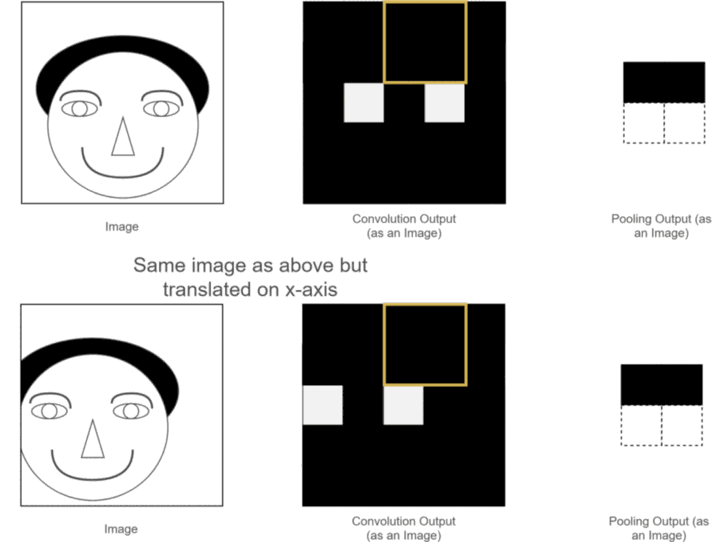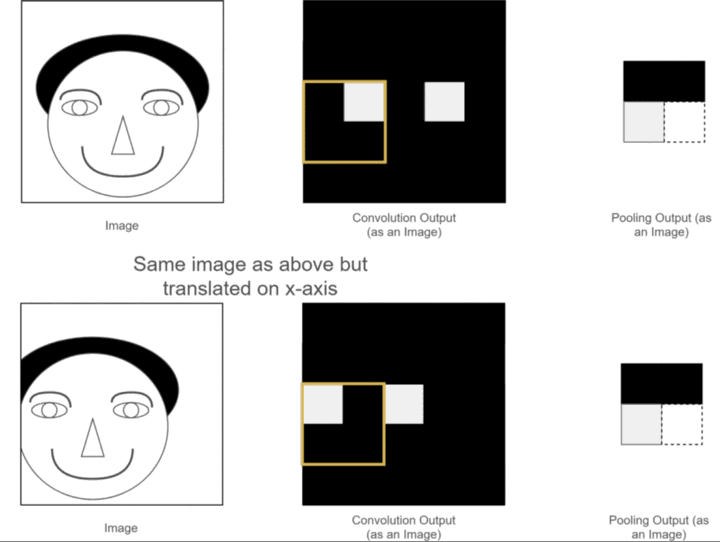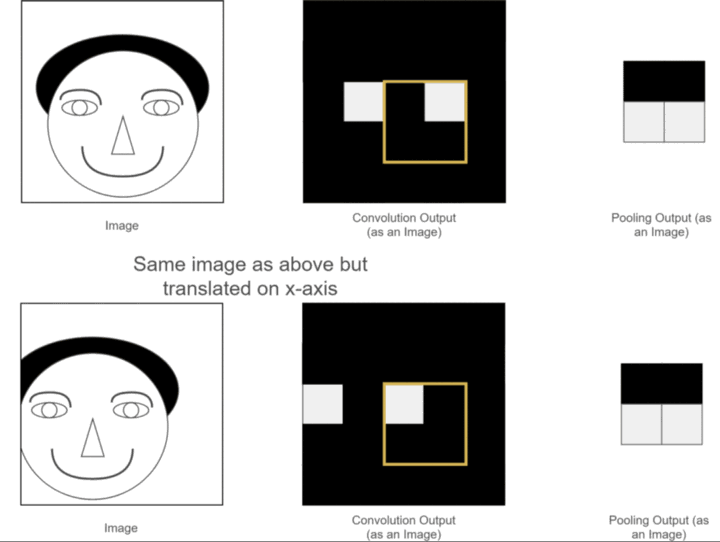
可以看到,两张原始图片的位置有所不同,一个是正常的,另一个是人的脑袋稍稍左移了一些,经过卷积操作后,得到各自对应的特征图,这两张特征图也和原始图片的位置相对应,一个眼睛特征的位置是正常的,另一个眼睛特征的位置稍稍左移了一些,虽然人可以分辨,但是经过神经网络计算后,就可能带来误差,因为应该出现眼睛的位置并没有出现眼睛,那应该怎么办呢?此时使用池化层进行池化操作,可以发现,虽然池化之前两幅图片的眼睛特征不在一个位置,但是经过池化之后,眼睛特征的位置都是相同的,这就为后续神经网络的计算带来了方便,此性质就是池化的平移不变性
全连接层
现在我们已经通过卷积和池化提取到了这个人的眼睛、鼻子和嘴的特征,如果我想利用这些特征来识别这个图片是否是人的脑袋该怎么办呢?此时我们只需要将提取到的所有特征图进行“展平”,将其维度变为1 × x,这个过程就是全连接的过程,也就是说,此步我们将所有的特征都展开并进行运算,最后会得到一个概率值,这个概率值就是输入图片是否是人的概率,这个过程如下所示:
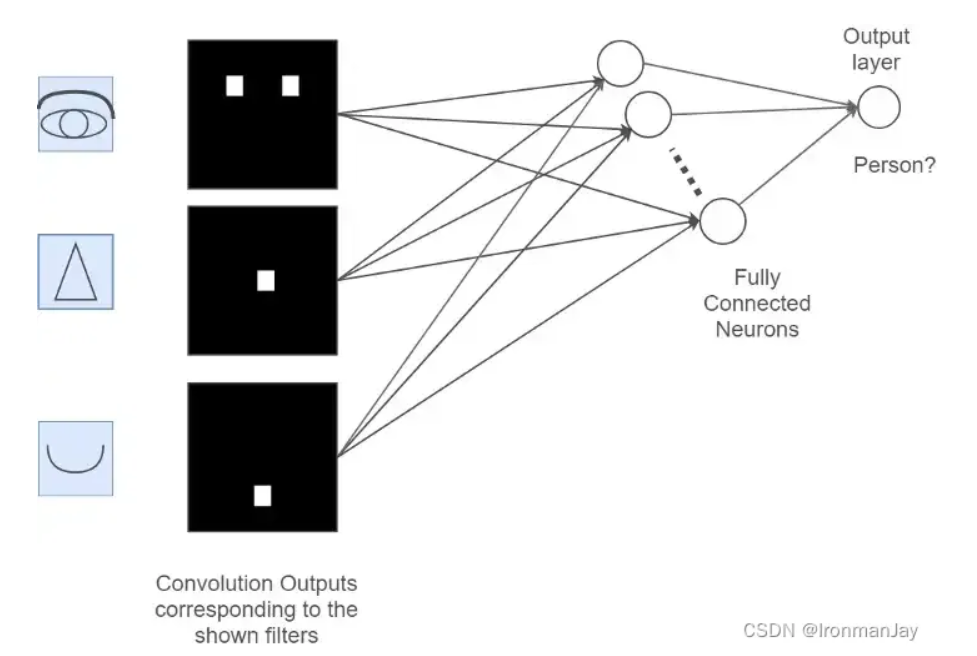
把之前的过程与全连接层结合起来,如下图所示:
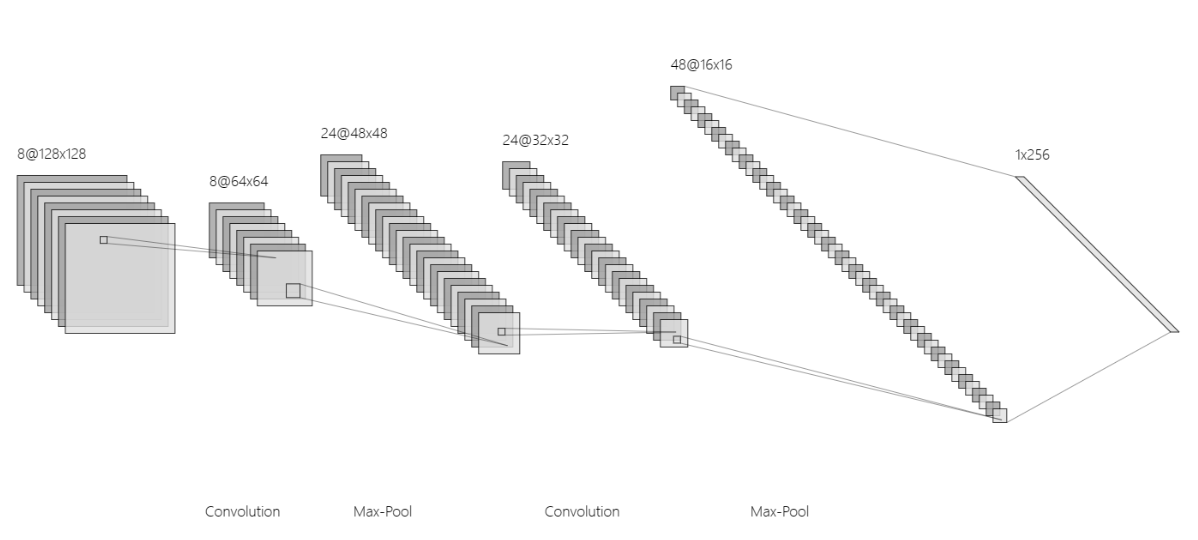
可以看到,经过两次卷积和最大池化之后,得到最后的特征图,此时的特征都是经过计算后得到的,所以代表性比较强,最后经过全连接层,展开为一维的向量,再经过一次计算后,得到最终的识别概率,这就是卷积神经网络的整个过程。
输出层
卷积神经网络的输出层理解起来就比较简单了,我们只需要将全连接层得到的一维向量经过计算后得到识别值的一个概率,当然,这个计算可能是线性的,也可能是非线性的。在深度学习中,我们需要识别的结果一般都是多分类的,所以每个位置都会有一个概率值,代表识别为当前值的概率,取最大的概率值,就是最终的识别结果。在训练的过程中,可以通过不断地调整参数值来使识别结果更准确,从而达到最高的模型准确率。
