损失函数
损失函数是机器学习里最基础也是最为关键的一个要素,通过对损失函数的定义、优化,就可以衍生到我们现在常用的机器学习等算法中
损失函数的作用:衡量模型模型预测的好坏
再简单一点说就是:损失函数就是用来表现预测与实际数据的差距程度
比方说:最小二乘法就可以作为损失函数来进行训练
学习率
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值
以梯度下降为例,来观察一下不同的学习率对代价函数的收敛过程的影响
当学习率设置的过小时,收敛过程如下:

当学习率设置的过大时,收敛过程如下:
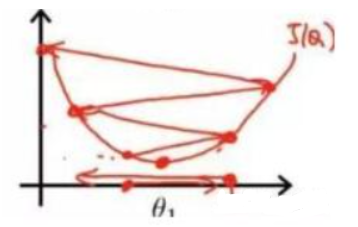
由上图可以看出来,当学习率设置的过小时,收敛过程将变得十分缓慢。而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
梯度下降算法
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降算法(Gradient Descent Algorithm)是最常采用的方法之一,也是众多机器学习算法中最常用的优化方法,几乎当前每一个先进的机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现。
梯度就是导数
梯度下降法就是一种通过求目标函数的导数来寻找目标函数最小化的方法。
梯度下降目的是找到目标函数最小化时的取值所对应的自变量的值,目的是为了找自变量X。
最优化问题在机器学习中有非常重要的地位,很多机器学习算法最后都归结为求解最优化问题。最优化问题是求解函数极值的问题,包括极大值和极小值。在各种最优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。
可以说,梯度下降就是深度学习的灵魂所在
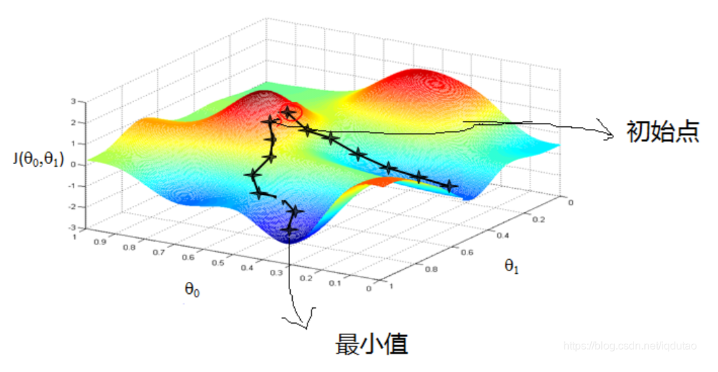
这里对于各种各样的梯度下降算法就不进行展开了
接下来就让我们进入代码实战试试